AI対策で、クエリファンアウトって良く聞くけど、良くわからない
端的にいうと、クエリファンアウトとは「検索した語句から考えられる次に検索するであろう語句や意図の集合体」であり、Googleの特許から生まれる概念です。
この記事の結論
クエリファンアウトを理解することは、LLMO・AIO対策の”なぜそうすべきか”を理解することと同義です。
- クエリファンアウトの正体:ユーザーの1クエリをAIが複数のサブクエリに自動分解→並列検索→統合して回答を生成する技術。AI OverviewsとAI Modeの両方で使われている
- 特許が示す本質:サブクエリは「キーワードの言い換え」ではなく「意図の変種(バリアント)」。比較型・探索型・意思決定型など、意図の角度そのものを変えて検索している
- 8タイプのサブクエリ:中でもタイプ4(確証・反証)とタイプ5(エンティティ取得)がLLMO対策に最も直結する
- コンテンツ設計の転換:「どのキーワードで1位を取るか」ではなく「AIが生成するサブクエリ群に、自社コンテンツは何%応えられるか」が新しい問い
本記事は特許の記述から読み取れる情報と、それに基づく当社の考察・実験結果です。Googleの内部アルゴリズムそのものではない点にご注意ください。
【全体像】クエリファンアウトは何をしているのか
改めて、クエリファンアウトとは何か?をGoogle Search Centralで公式に記述されている内容から紐解いていきましょう。
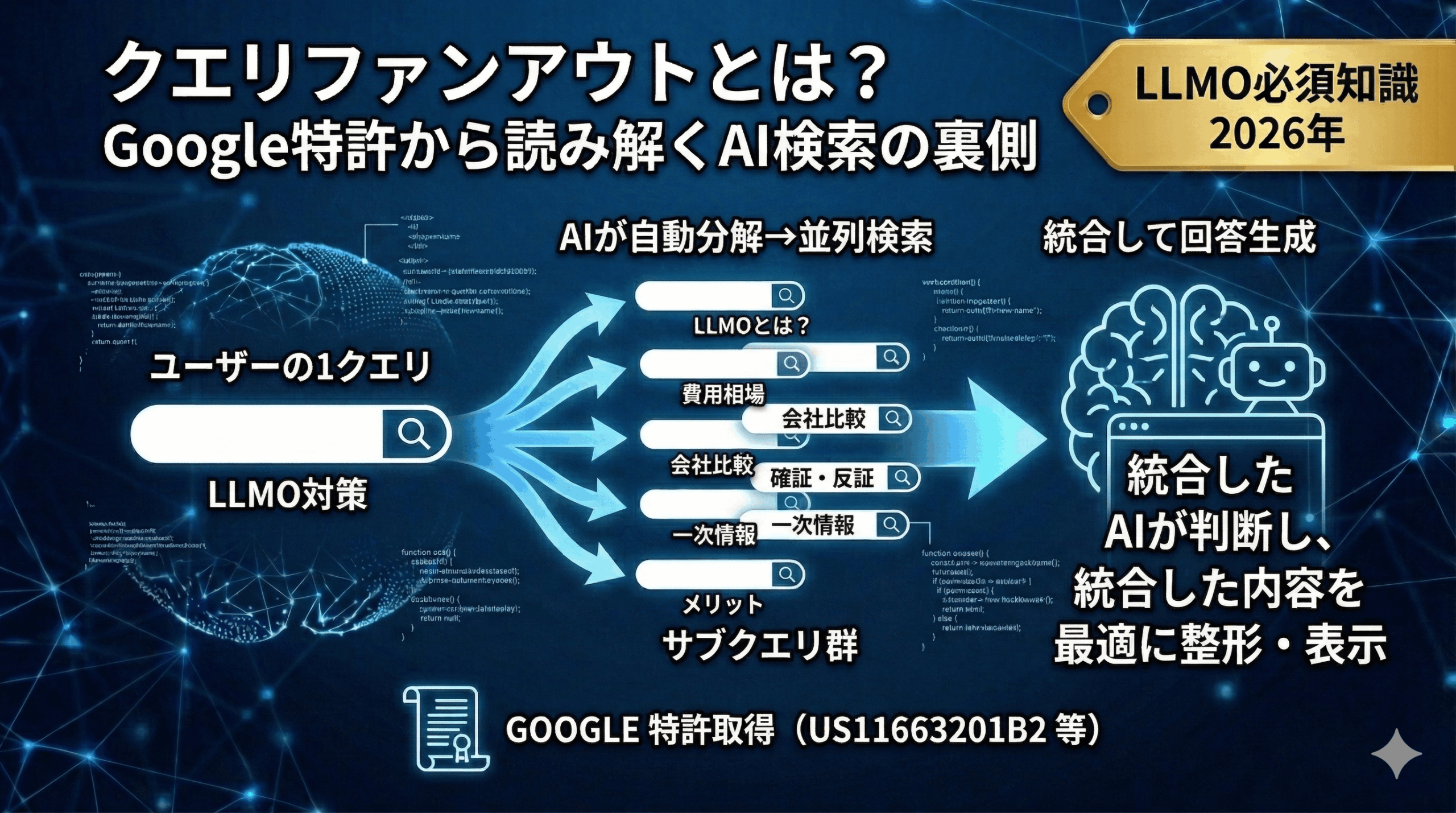
クエリファンアウトとは、ユーザーの1つの検索クエリをAIが複数のサブクエリに自動分解し、並列で検索して結果を統合する技術です。
AI検索はユーザーの入力をそのまま検索して情報を探しているわけではありません。検索の裏側で、AIが何十ものサブクエリ(派生となる疑問)を自動生成し、結果を束ねて回答を組み立てています。
処理は4ステップで、「分解」→「並列検索」→「統合」→「表示」です。
ステップ付きで解説すると下記の流れです。
例:「LLMO対策」と検索
AIが裏側で「LLMOとは何か」「LLMO SEOとの違い」「LLMO対策の具体的な方法」「LLMO 費用相場」「LLMO対策 会社」といったサブクエリを勝手に作り出す
1つ1つの回答や情報を個別に探し始める
ユーザーにとって信頼性のある情報を品質検証し、AIが合算して回答結果を生成
図にするとこういったイメージです。
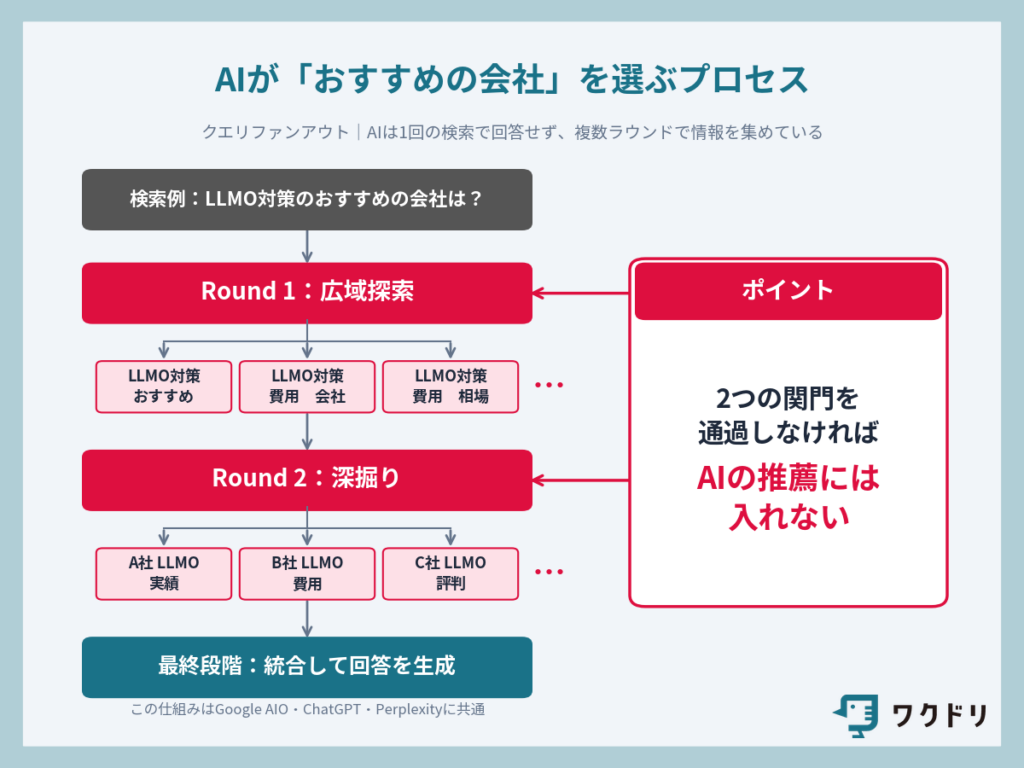
この流れは、2025年5月のGoogle I/Oで、AI Modeの中核技術としてクエリファンアウトをGoogleが正式に明言しています(Google公式ブログ)。AI OverviewsとAI Modeの両方で使われていますが、AI Modeのほうがサブクエリの生成量が多く、Deep Searchに至っては数百件規模です。
ここまでは他の記事でも解説されている内容なので、あまり新しい内容ではないかもしれませんね。特許を読みこんだうえで「これは想定外だった」と感じたポイントと、それを踏まえて実際に試したことを書いていきます。
”勝ち筋”は見えていますか?
Question 1/5
Q1.
競合と自社の「差分」や「立ち位置」を、
毎月定量的に把握できていますか?

特許を読んで見えた「想定外」!サブクエリはキーワードの言い換えではない
当社が重点的に読んだ特許は以下の3件です。
- US11663201B2:「Generating query variants using a trained generative model」、2018年出願、2023年取得
- US11769017:検索結果のサマリー生成に関する特許
- US20240289407A1:「Search with stateful chat」、セッション文脈を保持した継続検索
念のため書いておくと、特許に書かれていることが実際のGoogle検索でそのまま動いているとは限りません。特許は「こういう方法を考案した」という権利の記録であり、実装とイコールではないです。ただし、Google I/Oでの説明と特許の記述がかなり整合しているので、方向性としては参考になると当社は判断しています。
「バリアント」という言葉の意味がキーワードリサーチの前提を壊す
US11663201B2では、サブクエリのことを「query variants(クエリバリアント)」と呼んでいます。ここが最初の想定外でした。
バリアントは英語で「変種」や「亜種」という意味なので、「同義語に言い換える」のとは根本的に違います。
特許の記述を読むと、生成モデルは元のクエリに対して「異なるタイプの意図を強調するバリアント」を生成するよう訓練されています。たとえば比較型(A vs B)、探索型(how does X work)、意思決定型(best X for Y situation)。キーワードの表層ではなく、意図の角度そのものを変えていると言っても良いでしょう。
これを読むと、従来のキーワードリサーチの限界がはっきり見えるようになります。
GoogleキーワードプランナーやAhrefsは「人間が実際に検索窓に打ち込んだクエリ」の検索ボリュームを集計しています。しかしクエリファンアウトのサブクエリはAI内部で生成・処理されるもので、検索ボリュームという概念が存在しません。
要は、キーワードツールに出てこない検索語句で勝負が決まる世界の始まりです。
サブクエリ生成は「ランダムな連想」ではなく「体系的な意図分解」
で、もっと面白かったのが、US11663201B2がマルチタスクモデルによるバリアント生成を記述していることです。
そのなかで注目したい点は、1つの生成モデルが特許では7〜8種のバリアントタイプを同時に生成している点です。
ランダムに関連キーワードを思いつくのではなく、8つの軸で体系的にサブクエリを生成する点です。
- equivalent query(同義クエリ)
- follow-up query(フォローアップ)
- generalization query(汎化)
- specification query(具体化)
- canonicalization query(正規化)
- language translation query(言語翻訳)
- entailment query(含意)
- clarification query(明確化)
(原文)
Types of query variants can include, for example, an equivalent query, a follow-up query, a generalization query, a canonicalization query, a language translation query, an entailment query, a specification query, and/or a clarification query
ただし、この分類はそのままだとマーケターにとって使いにくいですよね。
株式会社ヴァリューズのロベルト氏をはじめ、業界では複数の特許(US20240289407A1等)とAI Modeの実際の挙動を掛け合わせて、コンテンツ設計に使いやすい8タイプに再分類しています。
- 曖昧さの解消
- 潜在ニーズの推測
- 深掘り
- 確証・反証の収集
- エンティティ取得
- 関連トピック拡張
- セッション文脈保持
- 個別化
本記事でもこの実務向け分類を採用します。
AIの情報収集には「型」がある。型があるなら、コンテンツ側もその型に合わせて設計できる。後ほど8タイプの詳細と、どのタイプがLLMO対策に効くかを掘り下げます。
生成されたサブクエリはAIが自己評価している
このあたりで特許を読むのがだいぶ楽しくなってきたんですが、さらに気になる記述があります。
制御モデル(control model)が「critic(批評家)」として機能し、生成されたバリアントを検索システムに投げた結果(レスポンススコアや回答の有無)に基づいて、「さらにバリアントを生成すべきか、ここで止めるか」を動的に判定する仕組みが記述されています。
言ってる意味が分からないので、もっと簡単な言葉に直すと下記になります。
AIがサブクエリを1つ投げるたびに、「返ってきた答えの質は十分か?」「まだ調べ足りないテーマがあるか?」をリアルタイムでチェックしている。十分だと判断すれば探索を打ち切って回答をまとめるし、足りなければさらにサブクエリを追加で生成する。
つまり、AIが独自に判断する際に、バリアントの中で「検索しても十分な回答が得られないもの」は却下され、最終的な回答には反映されません。
さらにニッチすぎるサブトピックは、検索システムから十分な回答が得られずに棄却される可能性があります。
専門性を上げるためにコンテンツを用意したほうが良い側面もありますが、「AIが質問しそうにないこと」を網羅しても言及や引用という意味では、効果が薄いかもしれません。カバーすべきは「AIが探索を続ける価値があると判断するサブクエリ」で、それはユーザーの検索行動パターンやナレッジグラフの構造から推測できるものです。
【8タイプのサブクエリ】どのタイプがLLMO対策に効くか、当社の評価と判断
サブクエリの8タイプ自体は複数の記事で紹介されているので、ここでは各タイプの「LLMO対策上の重要度」を当社の視点で格付けします。全タイプに当社の評価をつけているのは、おそらくこの記事だけです。
タイプ1:「曖昧さの解消」とタイプ8:「ユーザー属性への個別化」は当社判断「低~中」
- タイプ1:曖昧さの解消
- タイプ8:ユーザー属性への個別化
タイプ1は多義語の意味を特定するサブクエリ、タイプ8は位置情報や検索履歴に基づくサブクエリです。前者はLLMOのような新しい専門用語では多義性が低いため発火しにくく、後者はコンテンツ側で直接対応するのが困難(ローカルSEOの領域)。
この2つは正直、今すぐ気にする必要はないと考えています。あったとしても拾ってくれるはずです。
タイプ2:「潜在ニーズの推測」は当社判断「高」
ユーザーが言語化していない「本当に知りたいこと」を予測するサブクエリ。コンテンツ設計で最も直接的に活用できるタイプです。
「クエリファンアウト」と検索するユーザーの潜在ニーズは何でしょうか?
「クエリファンアウト 自社サイト 対策」「AI検索 引用されない 原因」「AI Mode いつ日本で使える」あたりがAIに生成されると想定できます。
このタイプに応えるには、「定義(What)」だけでなく「なぜ重要か(Why)」と「どう対策するか(How)」を記事に含める必要があります。
タイプ3:「詳細の深掘り」は当社判断「高」
元のクエリをさらに掘り下げるサブクエリ。専門記事ほど恩恵を受けやすいはずです。
本記事で特許番号や処理フローの詳細を書いているのは、まさにこのタイプへの対応です。
タイプ4:「確証・反証の収集」は当社判断「最高」
ある主張に対して、「支持する証拠」と「反論の両面」からソースを探すサブクエリ。当社としてはこのタイプが最も過小評価されていると感じています。
理由はシンプルで、メリットしか書いていない記事は確証サブクエリには拾われるが、反証サブクエリには拾われない。「LLMO対策は絶対にやるべき」としか書いていない記事は、AIが「LLMO対策 不要 理由」「LLMO対策 デメリット」というサブクエリを発行したときにスルーされる。
当社のAIO対策記事で「ただし、今すぐ慌てる必要はない側面もある」と書いているのは、実はこのタイプ4を意識しています。メリットとデメリットの両方を正直に書くことで、AIの両面探索に対して「どちらのサブクエリからも拾われる」ポジションを取れるものとしています。
当社がAIO対策記事で「AI検索トラフィックは全体の1%前後」「計測手段がまだない」というネガティブ情報もあえて正直に書いているのは、このタイプ4への対応です。「AIO対策 意味ある」「AIO対策 効果ない」のどちらの検索文脈からも拾われるポジションを狙っています。現時点では当サイトのDRが育っておらず効果検証はこれからですが、検証結果が出次第この記事にも追記する予定です。
タイプ5:「エンティティの取得」は当社判断「最高」
関連する企業・人物・製品の情報を取得するサブクエリです。
ナレッジグラフと直結しており、AIが回答文中でブランド名を「言及」するかどうかを左右する最重要タイプです。
「LLMO対策」で検索されたとき、AIが「LLMO対策 会社」「LLMO コンサルティング 比較」のようなエンティティ取得サブクエリを発行します。このサブクエリに対して自社が返される状態を作ることが、AIO対策記事で書いた「言及獲得」の技術的な裏付けです。
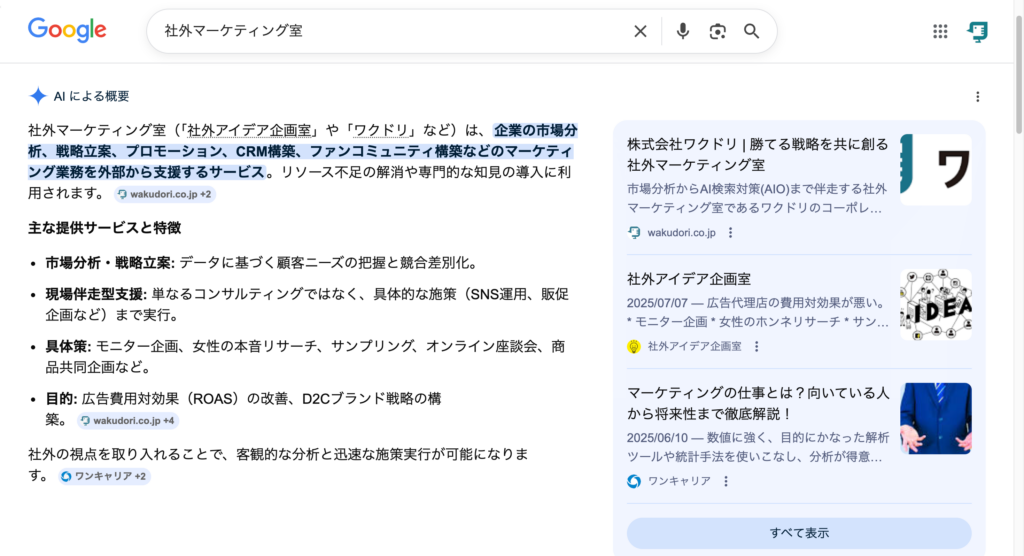
大手のサイトであればあるほど、多種多様な言葉や質問文で言及されるようになります。
タイプ6:「関連トピックへの拡張」は当社判断「高」
周辺テーマに広がるサブクエリ。「クエリファンアウト」から「RAG」「AIO対策」「ゼロクリック検索」へ展開されます。トピッククラスター構造の有効性を技術的に裏付けるタイプであり、後ほど「トピックオーソリティとの接続」で深掘りします。
タイプ7:「セッション文脈の保持」は当社判断「中」
AI Modeの会話型検索で先行質問の文脈を引き継ぐサブクエリ。日本でのAI Mode本格展開後に重要度が上がる見込み。FAQセクションがこの対応になります。
AIは集めた情報をどうやって「信用できる」と判断しているのか
平たく言えば、「複数のサブクエリから得られた回答同士が矛盾しないので、情報の中身は信用できそう」というロジックによって信頼性を確認しています。選挙の投票に似ています。
ここまで8タイプの評価を並べてきました。
このうちタイプ4で「反証サブクエリにも拾われるべき」と書きましたが、そもそもAIは集めた情報をどうやって「信用できる」と判断しているのか。その仕組みがCorroboration(確証)です。
クエリファンアウトで集められた情報は、無条件に回答に使われるわけではありません。Googleは「Corroboration(確証)」というプロセスで品質検証しています。複数のサブクエリから得られた情報を相互照合し、独立した複数のソースで裏付けが取れる情報を優先採用する仕組みです(US11663201B2)。
response(s) to variant(s) of an original query can be utilized to substantiate/corroborate response(s) to the original query and/or response(s) to other variant(s)
—
(日本語訳)
元のクエリのバリアントに対する応答は、元のクエリへの応答および/または他のバリアントへの応答を実証/確証するために利用できます。
unsubstantiated/uncorroborated response(s) can be determined and not utilized in provided output, and/or flagged as uncorroborated if utilized in provided output (e.g., flagged as ‘potentially fake’)
—
(日本語訳)
根拠のない/確認されていない回答は、提供された出力では使用されない可能性があり、提供された出力で使用されている場合は確認されていないものとしてフラグが付けられる(例:「偽造の可能性がある」としてフラグが付けられる)可能性がある。
ここに一次情報の価値が接続する
「Corroboration(確証)」は複数のサブクエリから得られた回答の整合性をチェックする仕組みです。裏を返すと、1つのサブクエリにしかヒットしないコンテンツより、複数のサブクエリに対して一貫した回答を返せるコンテンツのほうが採用されやすい。
「じゃあ、1つのサイト内にしか書いていない独自情報は不利じゃないか」と思うかもしれません。当社も最初はそう考えました。一次情報はそもそも自社しか持っていないから一次情報なのに、複数のサブクエリから一貫した裏付けが取れないと採用されにくいなら、矛盾しているように見えますよね。
でも実際は時間軸で解決すると判断しています。
独自調査を発信した時点ではソースは1つです。しかし、そのデータを他のメディアやブログが引用し始めると、「同じ事実を述べているソース」が複数になる。つまり一次情報は、発信した瞬間には「Corroboration(確証)」を突破できなくても、他者に引用されることでサブクエリのヒット面積が広がり、照合に成功しやすくなるメリットが大きいことになります。
単に「差別化できる」という話ではなく、「Corroboration(確証)」という品質検証を時間差で突破するための戦略だと考えています。
「一次情報を持て」と業界で言われる理由を、LLMの動作原理から説明すると上記のような整理になります。
構造化データが「Corroboration(確証)」の「照合精度」を上げる理由
もう一つ、特許を読んでから構造化マークアップに対して、より成功する確率が高い施策と改めて認識しています。
「Corroboration(確証)」で複数ソースの情報を照合するとき、AIは「ソースAの段落3」と「ソースBの段落7」が同じことを言っているかどうかを判定する必要があります。FAQPageスキーマやHowToスキーマで構造化されたコンテンツは、「この段落が何について述べているか」をAIが判定しやすい。(AIだけでなくGoogleにとっても構造や内容を正確に把握するために役立つ)
要は、構造化マークアップの価値は「AIに見つけてもらいやすくなる」だけではなく、「Corroborationの照合で一致判定に成功しやすくなる」という側面もあるのでは、というのが当社の仮説です。
本記事の設計プロセスを公開
ここまでの内容を踏まえて、実はこの記事自体がサブクエリ予測に基づいて設計されています。そのプロセスを公開します。
ステップ1:ターゲットKWに対して8タイプのサブクエリを予測する
本記事のターゲットKW「クエリファンアウト」を例に、8タイプで予測してみます。
- タイプ1(曖昧さの解消)/ タイプ8(個別化)
- 「クエリファンアウト」は専門用語で多義性が低く、位置情報依存でもない。この2タイプはほぼ発火しないと予測。
- タイプ2(潜在ニーズ)
- 「クエリファンアウト 対策方法」「クエリファンアウト SEO 影響」「AI検索 自社サイト 表示されない 原因」・・・「なぜ重要か」「どう対策するか」を知りたいユーザーに向けて、本記事では8タイプの評価セクションとコンテンツ設計フレームワークのセクションで対応しています。
- タイプ3(深掘り)
- 「クエリファンアウト Google特許 番号」「クエリファンアウト サブクエリ 種類」「Corroboration 仕組み」・・・特許番号・処理フロー・Corroborationの仕組みなど、技術的な詳細を求めるサブクエリに対して、特許解説セクションで対応しています。
- タイプ4(確証・反証)
- 「本当に効果あるの?」という懐疑的なサブクエリに対して、「ただし焦る必要はない」「DRが育っておらず効果検証はこれから」といった正直な記述で対応しています。
- タイプ5(エンティティ取得)
- 「どの会社が詳しいのか」を探すサブクエリ。これは記事の内容ではなく、Organizationスキーマや外部メディアでの言及など、サイト全体の設計で対応する領域です。
- タイプ6(関連トピック拡張)
- タイプ7(セッション文脈)
- 「もっと具体的に教えて」「実際どう対策すればいい?」はFAQで対応。
ステップ2:予測した穴を記事構成で埋める
予測したサブクエリに対して、本記事がどれに応えられているかをチェックします。
- タイプ2(潜在ニーズ)のサブクエリ
- 本記事の「コンテンツ設計への影響」セクションで対応。
- タイプ3(深掘り)のサブクエリ
- 特許解説セクションで対応。
- タイプ4(確証・反証)のサブクエリ
- 「ただし焦る必要はない」の記述で対応。
- タイプ5(エンティティ取得)
- 当社のOrganizationスキーマと外部言及が効いてくる領域。
- タイプ6(関連トピック拡張)
カバーできていない穴が見つかれば、それが次に書くべきコンテンツのテーマになります。当社はこれを「質問カバレッジ率」と呼んで、コンテンツ計画の指標に使い始めています。
ステップ3:見出し構成をサブクエリに対応させる
本記事の見出し構成は、ステップ1の予測結果をそのまま反映しています。「クエリファンアウトとは(タイプ2対応)」「特許の仕組み(タイプ3対応)」「8タイプの評価(タイプ2・3対応)」「Corroborationの考察(タイプ3・4対応)」「実際にやってみた(タイプ2・4対応)」「トピックオーソリティとの接続(タイプ6対応)」。
この設計方法をまとめると、「AIが生成するサブクエリを予測し、各サブクエリに対応するセクションを記事に配置する」。
これがクエリファンアウト時代のコンテンツ設計フレームワークです。
検索ボリューム「0」のクエリが勝負を決める
ステップ1(ターゲットKWに対して8タイプのサブクエリを予測する)をやってみると気づくのが、タイプによっては検索ボリュームが「0」のサブクエリが含まれることです。
「クエリファンアウト Google特許 番号」は検索ボリューム0。
「Corroboration 仕組み」もデータなし。
一方で、タイプ6の「AIO対策」(Vol:2,900)やタイプ5の「LLMO コンサルティング」(Vol:590)は普通に検索ボリュームがあります。(Googleキーワードプランナー)
つまり、従来のキーワードリサーチで拾えるサブクエリと、拾えないサブクエリが混在している状況です。そのため、一般的なキーワードツールだけを頼りにコンテンツを設計すると、特にタイプ3(深掘り)やタイプ4(確証・反証)のサブクエリを取りこぼす可能性があるということですね。
ここから当社が考えているのは、「キーワードの検索ボリューム」から「質問のカバレッジ率」への指標転換です。あるテーマに対してAIが生成するであろうサブクエリ群を仮説ベースでリスト化し、自社コンテンツがそのうち何%に回答できているかを評価する。
正直に言うと、この考え方はまだ仮説段階で効果測定の方法も確立していません。ただ、クエリファンアウトの仕組みを特許ベースで理解した上での論理的帰結として、方向性は合っていると考えています。
トピックオーソリティとの接続!なぜ「面」で記事を持つドメインが有利なのか
最後に、クエリファンアウトのタイプ6(関連トピックへの拡張)から導かれる仮説を共有します。
タイプ6では、AIが元のクエリから周辺テーマへサブクエリを展開します。
「LLMO対策」→「AIO対策」「RAG」「E-E-A-T」「クエリファンアウト」。
このとき、展開先のサブクエリで返ってくる結果がすべて同一ドメインのコンテンツだったらどうなるか。
AIは「このドメインはこのテーマ全体に詳しい」と判断し、回答の複数箇所でそのドメインを参照する確率が高まるはずです。SEO業界で言われる「トピックオーソリティ」が有利な理由を、クエリファンアウトの仕組みで説明できると当社は考えています。
冒頭で触れた競合記事の一つが上位表示されている理由も、おそらくここにあります。コンテンツの深さではなく、LLMO・AI Mode・AI Overview・RAGといった関連テーマの記事をすべて持っていてトピッククラスターが完成していることが効いている。
当社のサイト設計でLLMOとはをハブにしてAIO対策・クエリファンアウト(本記事)・今後公開するRAG記事・E-E-A-T記事を内部リンクで密に接続しているのは、このタイプ6の仮説に基づいています。個々の記事の質だけでなく、テーマ全体での「面の占有率」が勝負を分ける。
そしてこの「面の占有率」を定量的に測る方法こそ、先ほどの「質問カバレッジ率」です。テーマ全体で30〜40のサブクエリが予測されるとして、自社ドメインがカバーしているのが25個ならカバレッジ率70%。残りの30%が次に書くべき記事です。
AIO対策の記事でも書いたことですが、AI検索からのトラフィックは現時点で全体の1%前後です。だから焦る必要はないですが、その1%の世界でどう戦うかの設計図は、今のうちに引いておくべきだと考えています。
よくある質問(FAQ)
クエリファンアウトに関するよくある質問をまとめます。
まとめ
クエリファンアウトは「AIが裏側で何を検索しているか」を知るための鍵です。特許を読んで見えてきたのは、AIの情報収集には「型」があり、その型に合わせてコンテンツを設計できるということでした。本記事の要点を振り返ります。
- サブクエリは「キーワードの言い換え」ではなく「意図の変種(バリアント)」。特許US11663201B2に7〜8種のタイプが記述されている
- 業界ではこれを実務向けに8タイプに再分類。中でもタイプ4(確証・反証)とタイプ5(エンティティ取得)がLLMO対策に最も直結する
- Corroboration(確証)はサブクエリ回答の整合性チェック。一次情報は時間差でこの仕組みを突破できる
- 従来のキーワードリサーチでは拾えないサブクエリが存在する。「質問カバレッジ率」という新しい設計指標が必要になる
- トピッククラスター構造が有利な理由は、タイプ6(関連トピック拡張)のサブクエリに面で対応できるから
繰り返しになりますが、AI検索からのトラフィックは現時点で全体の1%前後です。だから今日やるべきことの1番目ではないかもしれない。ただ、その1%の世界のルールが特許に書いてある以上、設計図だけは先に引いておいて損はないはずです。
当社では、LLMO・AIO対策を含むマーケティング戦略の設計から実行まで一気通貫で支援しています。「自社の場合、何番目にやるべきか」から一緒に考えたい方は、お気軽にご相談ください。
”勝ち筋”は見えていますか?
Question 1/5
Q1.
競合と自社の「差分」や「立ち位置」を、
毎月定量的に把握できていますか?