「E-E-A-Tを高めましょう」
正直、この言葉を聞いて「で、具体的に何するの?」と思った方が大半ではないでしょうか。
当社にも月に数件、こういう相談が来ます。「著者プロフィールを整えた」「構造化データも実装した」。なのにChatGPTで自社名が出てこない、みたいなものですね。
問題は「信頼をWeb上でどう構築するか」の全体像が見えていないことです。
著者プロフィールや構造化データは信頼を”伝える手段”であって、信頼そのものではありません。AIが信頼と判断するのは、Web上の複数の文脈で自社名が専門領域と紐づいて繰り返し登場している状態です。被リンク(URLが貼られること)とは違い、リンクがなくても「○○の分野なら△△社」と言及されていれば、それがLLMのトレーニングデータに刻まれます。
この記事の結論
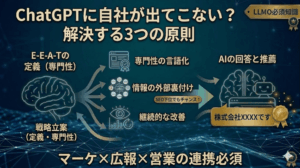
Web上で自社名が専門領域と紐づいて登場する状態を作ること=信頼性の担保が一番難しいが肝である
- E-E-A-Tは直接的なランキングファクターではないが、LLMが情報源を選ぶ際にE-E-A-Tと構造的に同じ信頼判断を行っている。「SEOの評価基準」と「LLMの情報選別ロジック」を分けて理解することが出発点
- Googleは品質評価ガイドラインでTrust(信頼性)を最重要と明記。AI検索でも同じだが、信頼の構築には2段階ある。第1段階は自社サイトの信頼シグナル整備、第2段階はWeb上で自社名が専門領域と紐づいて登場する状態を作ること。後者がLLMの信頼判断を動かす本丸
- Experience(経験)がAI時代に最も差がつく理由は、一次情報が「他サイトに参照される元ネタ」になり、LLMのトレーニングデータ内での出現頻度を構造的に高めるから
- 企業が目指すべきゴールは「引用(Citation)」ではなく「言及(Mention)」。この違いを混同するとゴール設定を誤る
AIO対策記事の「表示されるための4つの条件」とLLMO対策記事の「具体的に何をすればいいの?」を深掘りしながら、E-E-A-Tの各要素をLLMの動作原理付きで解説していきます。
E-E-A-T×LLMO対策で今すぐやるべき5つのこと
まず、「何をやればいいか」を先に渡します。理由の深掘りは後半で書くので、まずは全体像を掴んでください。
”勝ち筋”は見えていますか?
Question 1/5
Q1.
競合と自社の「差分」や「立ち位置」を、
毎月定量的に把握できていますか?

① 信頼の土台を整える(Trust)
信頼の構築は2段階あります。
- サイトの信頼シグナルを整えること
- Web上で自社名が専門領域と紐づいて繰り返し登場する状態を作ること
サイトの信頼シグナルを整えること
第1段階は「サイトの信頼シグナルを整える」ことです。
- 会社概要に代表者名・所在地・連絡先を明記する
- 記事ごとに著者名と経歴を設置する
- 数値データにはソースURLを添える
- HTTPS・robots.txt・サイトマップの正常動作を確認し、AIが認識できる状態を作る
これはAIに「信頼性を判断する材料」を渡すための前提条件であり、Webに携わっている人であれば「当たり前」としていることです。しかし、ここが抜けていると、どんなに良いコンテンツを出してもAIは「発信元不明」として認識することもあり得ます。
もちろん、これだけでは全然足りず基礎中の基礎の項目です。著者情報を整えたところで、AIが「この著者は信頼できる」と判断するわけではないからです。
Web上で自社名が専門領域と紐づいて繰り返し登場する状態を作ること
第2段階が本丸で、「Web上で自社名が専門領域と紐づいて繰り返し登場する状態を作る」こと。
- 業界メディアの記事に社名が登場する
- 専門家として寄稿する
- SNSで継続的に発信する
- 顧客や他社が自社名に言及する
こうした「自社サイト以外での言及」が積み重なることで、LLMは「このブランドはこの領域で認識されている存在だ」と学習します。
これは被リンク(URLが貼られること)とは似て非なるものです。LLMはリンクの有無ではなく、文脈の中でブランド名と専門テーマが一緒に登場する頻度を見ています。リンクが1本もなくても、業界メディアの記事に「○○分野に詳しい△△社によると」と書かれていれば、それはLLMにとって信頼のシグナルになります。
この第2段階の具体的なやり方は④で後述します。
② 自社にしか出せない一次情報を作る(Experience)
自社の運用データ、顧客アンケート、施策のビフォーアフター数値。これを最低でも1記事に1箇所は埋め込む。
「でもうちに出せるデータなんて…」と思うかもしれません。
でも、たとえば「当社が支援する飲食業20社のうち、AI Overviewに1回以上表示された企業の共通点は〜」これだけで一次情報になります。(ただし言うだけでなく証拠となるキャプチャや分析結果の途中の数字変化等が必要)
大規模な調査でなくて良いので、自社の現場から出た数字がそのまま武器です。
当社の経験上、特に効果が高いのは「失敗事例」です。
「○○をやったけど効果がなかった」という情報は、他のサイトがまず出しません。AIにとっても「このソースは実際にやった結果を書いている」という経験の証拠になります。
③ FAQを「AIが拾いやすい形」で設置する(Expertise)
記事末尾にFAQセクションを置き、Q文はユーザーが実際にAIに投げかける形にするようにするとイメージしやすいでしょうか。
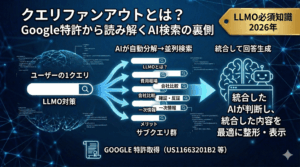
端的に「E-E-A-Tとは」と表現するのではなく、ユーザーが本当に人に質問するかのような形式、つまり、「E-E-A-Tを高めるには具体的に何をすればいいですか?」のようにすると自然なQとなります。この書き方はクエリファンアウトで解説したサブクエリの「具体化(specification query)」に直接対応します。
加えて、FAQPageスキーマ(JSON-LD)を実装することで、より正確な情報を伝達することが可能となります。
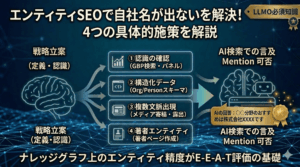
④ 外部からの言及を増やす(Authoritativeness=信頼構築の本丸)
①で書いた「信頼の第2段階」がAuthoritativenessです。
これらは一部の例ですが、プレスリリース配信をした後の拡散、業界メディアへの寄稿、SNSでの専門テーマ発信が挙げられます。
LLMはリンクの有無ではなく、文脈の中でブランド名と専門テーマが一緒に登場する頻度を見ています。具体的な施策と事例は後半で詳しく書きます。
⑤ 構造化マークアップでAIの意味解釈を助ける
Organization、FAQPage、Article、HowToといった構造化データの実装です。
Googleのクローラーがコンテンツのセマンティクスをパース(分解して認識)する精度が上がり、AIOへの表示率向上にも間接的に寄与します。なお、必ずしも構造化データを実装しないと効果がないという訳ではありません。
構造化データはSEOの順位を上げるための施策でもなければ、AIに言及されるために直結する施策でもなく、発信者が提供するコンテンツの内容を誤認することなく正しくAIやGoogleに理解してもらうための補助機能です。
ここまでが「やるべきこと」のリストです。
競合記事の多くは、ここで話が終わります。しかし、施策リストを渡しても成果が出る企業と出ない企業が出てしまう「原因や正体」は何なのか?という点を見逃してはいけません。
施策の前にやるべきこと:「AIからの見え方」を確認する
ここから、当社がこの記事で一番伝えたいことです。
ChatGPT、Perplexity、Google AI Modeに、自社の業界に関する質問を投げてみてください。
「○○業界でおすすめの会社は?」「○○で困っているんだけど、どこに相談すればいい?」
自社名は出ますか?出ませんか?
出ないなら、代わりにどの会社名が出ていますか?
その会社はどんなコンテンツを持っていて、どこで言及されていますか?
海外の調査でもこの傾向は明確に出ていて、BrightEdgeのデータではAIOで引用されるソースのうち従来のGoogle検索トップ10に入っているのは約17%にとどまり(ALM Corp, 2026)、Ahrefsの2025年8月の調査ではAIが引用するURLの80%がそのクエリのGoogle検索トップ100にすら入っていないと報告されています。
当社でも独自に調査した結果があり、GoogleのAI OverViewsで言及される公式サイトが、そのキーワードのSEO順位で何位にいるかを比較したところ、SEO11位以下であってもAIに言及・推薦されるケースは73.5%にのぼっていました(LLMO対策記事で詳細を公開)。

このことからも、SEOで競合に勝てなくても、AI検索で推薦される可能性は十分にあるということであり、ドメインパワーの勝負ではなく「AIに信頼される情報源かどうか」の勝負に土俵が変わっています。
この分析をしないまま「著者プロフィールを充実させよう」「FAQを入れよう」と始めるのは、自社の健康診断をしないまま「とりあえず毎日走ろう」と決めるのと同じ。走ること自体は悪くないけど、体調が悪いのなら先に治療が必要となります。
当社ではこのステップを「AIポジショニング調査」と呼んでいます。E-E-A-Tのどの要素が足りないかは、現在地を見なければ判断できません。
そもそもE-E-A-Tとは?(LLMO視点での再定義)
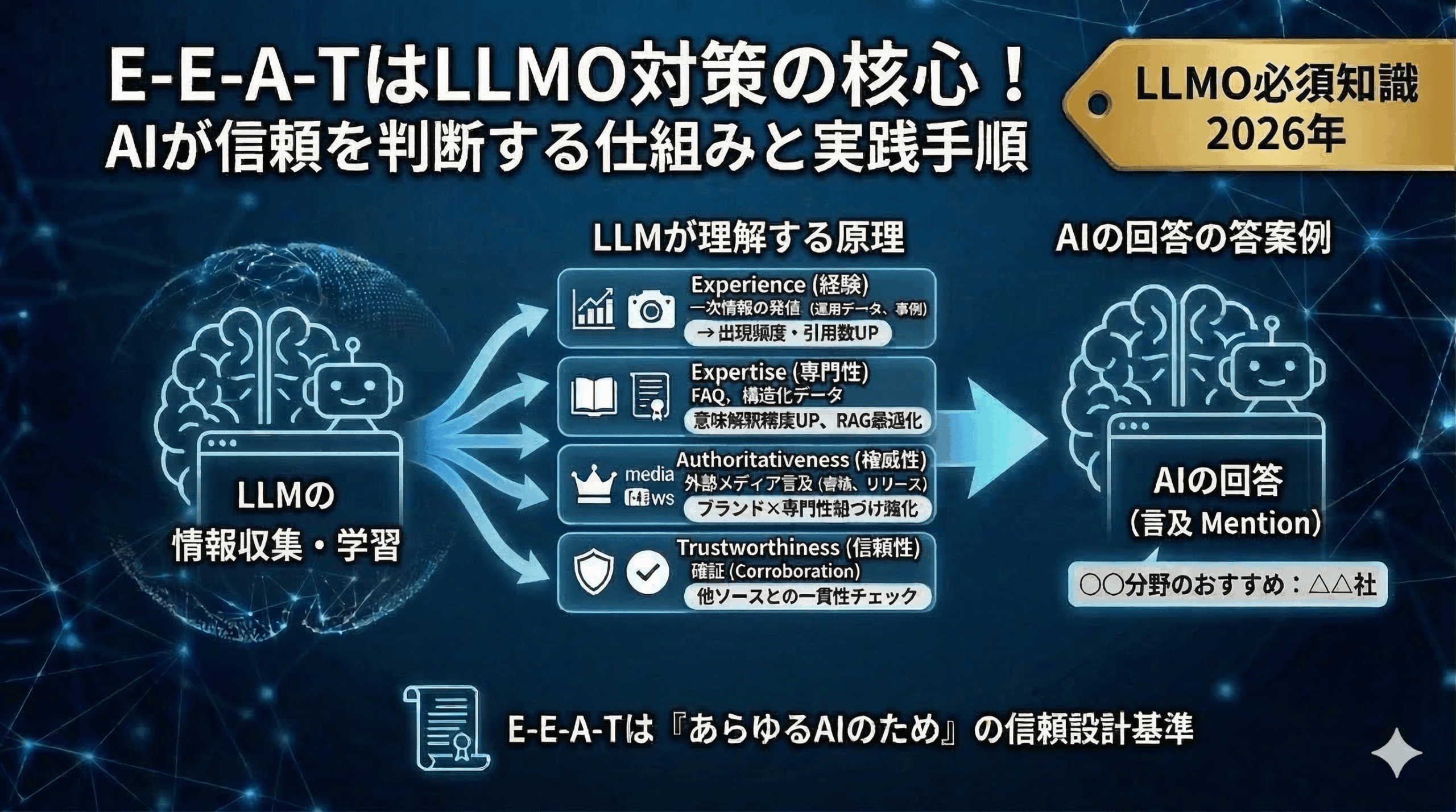
E-E-A-Tは、Googleの品質評価ガイドラインで定められた評価枠組みです。2022年12月に従来のE-A-TにExperience(経験)が追加され4要素になりました(Google公式ブログ)。
世界中に10,000人以上いる品質評価者が検索結果の品質を手動評価するための基準であり、その結果がアルゴリズム改善にフィードバックされるという間接的な経路で影響します(Search Quality Rater Guidelines, 2025年9月版)。
じゃあなぜLLMO文脈でそこまで騒がれるの?
ここが面白いところで、LLMが情報を取捨選択するプロセスが、品質評価者の判断基準と構造的に同じだからだと当社は推察しています。
LLMはトレーニングデータ内で「複数ソースから一貫して参照されている情報」「権威あるドメインに掲載されている情報」「専門的文脈で繰り返し言及される情報」に高い重みを与える傾向があります。このロジックは、Experience、Expertise、Authoritativeness、Trustworthinessの4要素そのものです。
つまり、Googleの品質評価基準に合致するコンテンツは、LLMにとっても信頼に値する情報源として扱われやすい。E-E-A-Tは「Googleのため」ではなく「あらゆるAIのため」の信頼設計基準として機能し始めている、というのが当社の見立てです。
なぜTrust(信頼性)がすべての土台なのか?
品質評価ガイドラインはTrust(信頼性)を「E-E-A-Tファミリーの中で最も重要」と明記しています。
Trust is the most important member of the E-E-A-T family because untrustworthy pages have low E-E-A-T no matter how Experienced, Expert, or Authoritative they may seem.
品質評価ガイドライン
E-E-A-Tは全業種に求められますが、医療・金融・法律などのYMYL(Your Money or Your Life)領域では評価基準やチェックポイントがさらに多くなるため、該当する業種の方は一段階厳しい目線で取り組む必要があります。
ではLLMはどうやって信頼判断をしているのか。ここでクエリファンアウトの記事で解説した「確証(Corroboration)」のプロセスが効いてきます。
AIはユーザーの検索を複数のサブクエリに分解し、並列で情報を取得したあと、取得した情報同士を照合して矛盾がないかチェックします。あるサイトの情報が他の権威あるソースと一致していれば信頼度が上がり、矛盾していれば除外されます。
ここがポイントで、確証プロセスは単に「正しいかどうか」だけを見ているのではなく、「他の信頼できるソースでも同様のことが書かれているか」を見ています。つまり、自社サイトの情報が孤立していると、たとえ内容が正しくても確証が取れず信頼度が低くなります。これが「自社サイトだけで頑張っても限界がある」理由であり、外部言及が必要な構造的な背景です。
これがLLMにとっての「信頼判断」の軸であり、この判断は、人間の品質評価者がやっていることとほぼ同じ構図となります。
当社が支援の現場で見てきた限り、「AIに言及されない」と悩む企業の7〜8割は、コンテンツの質の問題ではなく第2段階の「Web上で自社名が専門領域と紐づいて繰り返し登場する状態を作れていないこと」が該当しています。
一次情報がLLMの重みを変える!Experience(経験)の動作原理
Experience(経験)は2022年に追加された最も新しい要素で、AI時代に最も差がつく要素でもあります。その理由をLLMの動作原理から考察します。
LLMのトレーニングデータはWebから収集された大量のテキストですが、その中で「複数のサイトが参照元として引用している情報源」は出現頻度が飛躍的に高くなります。
たとえば、ある企業が自社の顧客データをもとに「○○業界の平均CVRは3.2%」と公表したとします。その数値が5つの業界メディアに引用されれば、LLMのトレーニングデータ内にその情報は最低6回(元記事+引用5記事)登場します。一方、他社サイトのコピーコンテンツは、たとえ内容が正しくても引用されないので出現頻度は1回きりです。
この構造から導かれる仮説はシンプルです。他サイトに引用される「元ネタ」になることが、LLMの重みづけ(言及対象の可能性)を高める最短経路となります。
AIO対策の記事でも「一次情報を出しましょう」と書きましたが、その理由を「いい記事を書くため」で終わらせてはいけません。一次情報の発信は、LLMのトレーニングデータ構造そのものに介入する行為です。
では中小企業が出せる一次情報とは何か。
- 「当社が支援する○○業界30社のデータでは、AIに言及された企業の共通点は著者情報の整備率が100%だった」のような集計データ
- 施策実施のビフォーアフター(Search Console・GA4のスクリーンショット付き)
- 「やってみたが効果がなかった施策」の失敗事例——他サイトが出さない情報だからこそ一次情報としての希少性が高い
こういった、「他社に出せないデータ」の積み重ねが重要となります。
当社の別記事:注文住宅業界でInstagramを活用することで指名検索が増えたという事例は、実際に当社で実行したSEO対策およびInstagramの支援結果=一次情報の最たる例だと考えています。
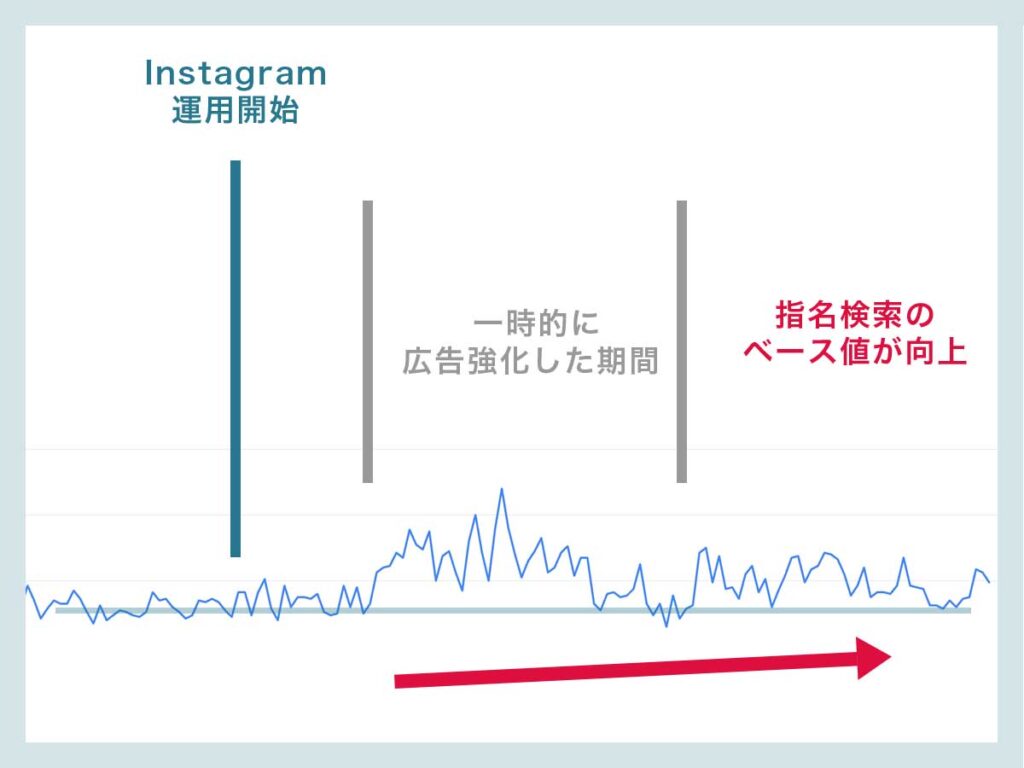
当社は、AI時代に言及される環境を作るWebマーケティング支援会社なので上記のような事例を表現できますが、事業者側でもコンテンツ記事を発信するのであればぜひ自社の研究結果やデータを訴求することを推奨します。
FAQと構造化データがAIに効く「本当の理由」
「FAQを置きましょう」「構造化マークアップを入れましょう」
きっとLLMO対策を検討あるいは実施しているなら、上記のような説明がされている記事をきっと多く読んでいることでしょう。でも「なぜLLMがそれを好むのか」まで踏み込んでいる記事を見たことありますか?
FAQがLLMに刺さる理由
LLMはStack Overflow、Quora、Yahoo!知恵袋のような巨大Q&Aデータベースを大量に学習しています。つまり「問いと答え」の対構造は、LLMにとって最もパース(変換・抽出・理解)しやすい最小意味単位となっているんです。
さらに、AI検索ではRAG(Retrieval-Augmented Generation=検索拡張生成)が活用されています。RAGは外部ソースからパッセージ(文章の断片)を取得してLLMの回答に組み込む仕組みです。このパッセージ抽出において、FAQの「1つの質問に対する1つの回答」は、まさに抽出に最適な粒度として機能します。
たとえば「E-E-A-Tについて」ではなく「E-E-A-Tを高めるには具体的に何をすればいいですか?」。このように書けば、AIのサブクエリに引っかかりやすくなる可能性が高まります。
構造化マークアップが効く理由
Googleのクローラーは構造化データ(schema.org)を使ってコンテンツの「意味」をパース(変換・抽出・理解)しています。AIOを含むLLMベースの検索では、このセマンティック解釈がパッセージ抽出の精度に直結します。
構造化データが正しく実装されていれば、AIは「このページはE-E-A-Tについて書かれている」「このFAQはE-E-A-Tの高め方に答えている」と意味レベルで理解できます。
逆に構造化データがなければ、AIにとっては「読めるけど意味が曖昧なテキストの塊」。同じ内容でも、構造化されている方が引用される確率が上がるのは当然と言えます。
LLMO(GEO)では「引用」ではなく「言及」を狙う
①のTrustで書いた「信頼構築の第2段階」を、ここで具体的に掘り下げます。
まず前提として、引用(Citation)と言及(Mention)の区別を確認してください。AIO対策の記事で詳しく書いていますが、ここでも改めて整理します。
- 引用(Citation):AIOがURLをソースとして参照・リンクすること → コンテンツ側の評価
- 言及(Mention):AIの回答文中に会社名やサービス名が登場すること → ブランド側の評価
BrightEdgeの調査によると、ChatGPTはブランドを引用する3.2倍の頻度で言及しています(BrightEdge: Brand Mentions vs. Citations)。URLを貼ってもらう機会よりも、社名を出してもらう機会のほうが3倍以上ある。
一方で、GeminiやAIモードで当社のように引用(赤枠)されたとしましょう。
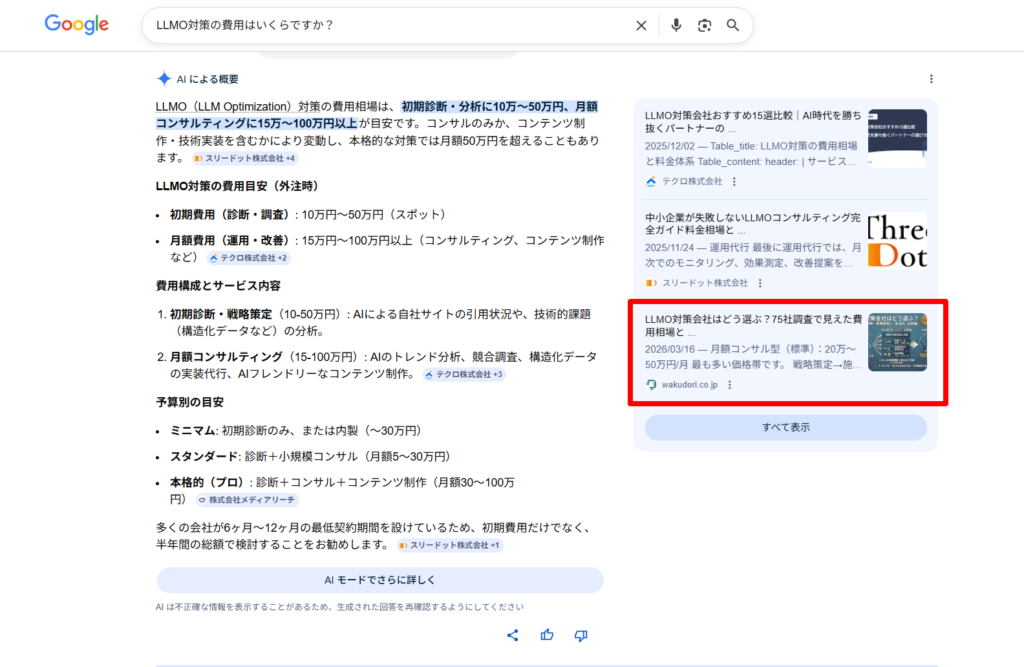
LLMO対策の費用はいくらですか?
この結果として、赤枠のように当社のLLMO対策の相場に関する記事が引用されたとしても、ほぼクリックされることなないと実体験からも感じています。
ここがSEOの常識と大きくずれるポイントです。
従来のSEOでは「被リンクを獲得する」がゴールでした。
理由としては、リンクが貼られることで、Googleのページランクが上がるからです。
しかし、LLMはページランクを参照しているわけではありません。
LLMが見ているのは、トレーニングデータの中で「このブランド名が、信頼できる文脈の中で、専門テーマと一緒にどれだけ登場しているか」であって、リンクの有無は直接には関係ない。(間接的には大いに関係あります)
だから「被リンク獲得」に投資するだけでは、AI時代の信頼は積み上がりません。目指すべきは「リンクがなくても社名が出てくる状態」です。
では具体的にどうするか。当社が支援先で実際にやっている施策を挙げます。
- 月1回のプレスリリース配信(PRTIMESなど)。業界メディアが取り上げてくれれば、リンクがなくても「○○分野の△△社」という言及がWebに残る
- 業界メディアへの寄稿 or 取材記事の獲得(四半期に1回が目安)。「著者:△△社 勝浦氏」と署名が入ること自体が、LLMにとってのブランド×専門性の紐づけになる
- X(旧Twitter)・YouTubeで「自社名 × 専門テーマ」を紐づけた発信を週2回以上。AIのトレーニングデータにはSNSの投稿も含まれている
- Googleビジネスプロフィールの最新化。ナレッジグラフへのエンティティ登録の第一歩であり、AIが「この会社は実在する」と判断する材料になる
- schema.orgのOrganizationスキーマで自社情報を構造化。本社所在地、代表者、事業内容、SNSリンクを含める
1つ、当社が見て「なるほど」と思った事例を紹介します(クライアント名は伏せます)。
ある中小企業が業界誌に2回寄稿しただけで、ChatGPTの回答に社名が出るようになりました。
サイトのコンテンツ量は競合の1/3以下。ドメインパワーも弱い。でも、信頼できるメディアで「○○分野の△△社」と書かれたことが、LLMの判断を動かした。被リンクの本数ではなく、「どれだけ多くの文脈で、自社名が専門領域と一緒に登場しているか」。
これがAI時代の権威性であり、信頼の正体です。
当社の独自調査であるSEO11位以下のサイトがAI OverViewsで言及されるケースは73.5%と高い数値をお伝えしたように。ドメインパワーの勝負ではない世界が、もう始まっています。
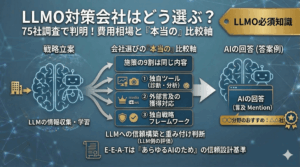
E-E-A-T×LLMO対策の「正しい進め方」
ここまでの内容を時系列に整理します。よくある「チェックリスト」ではなく、順番が重要です。
AIポジショニング調査(1日でできる)
ChatGPT、Perplexity、Google AI Modeそれぞれに自社業界の質問を10個投げる。自社名が出るか、競合名が出るか、何も出ないかを記録する。
Trust第1段階|サイトの信頼シグナル整備(1〜2週間)
著者情報、会社概要、ソース明記、HTTPS等、発信内容の確認。ここが整っていなければ他の施策は後回し。
一次情報の発信設計(1ヶ月〜)
自社の現場から出せるデータを洗い出し、コンテンツに組み込む計画を立てる。まずは既存記事に1箇所ずつ独自データを追加するところから。
FAQ・構造化データの実装(2週間〜)
コンテンツページごとに、そのページに対応するFAQセクションを設置し、FAQPageスキーマを実装。Q文はユーザーのプロンプト型に統一することで精度を上げます。
Trust第2段階|外部言及の獲得(継続)
プレスリリース、寄稿、SNS発信。月単位で「Web上に自社名×専門領域の言及が何件増えたか」を計測する。ここが信頼構築の本丸です。
再調査と改善(四半期ごと)
STEP1と同じ方法でAIポジショニングを再調査し、変化を確認。出てこなかったAIで出るようになったか、言及のニュアンスが変わったか。
「全部やる余裕がない」という場合、STEP1とSTEP2だけでも先にやってください。
分析と信頼の土台がないまま施策を積み上げても、お金と時間が溶けるだけです。当社に相談に来る企業の多くが、ここを飛ばして施策から入っています。
よくある質問
まとめ
E-E-A-T施策の正しい順番を改めて整理すると、調査(AIからの見え方を確認)→ 第1段階の信頼整備(サイトの体裁)→ 一次情報発信 → 構造化データ・FAQ実装 → 第2段階の信頼構築(外部言及の獲得)。LLMO対策の全体像、AIOの表示条件、クエリファンアウト、ゼロクリック検索とあわせて理解することで、点の施策が線の戦略になります。
「何から始めればいいかわからない」なら、ChatGPTを開いて自社の業界に関する質問を投げてみてください。それが現在地の確認であり、E-E-A-T施策の第一歩です。