「エンティティSEO」と検索してこの記事にたどり着いた方は、おそらく次のどれかに当てはまるはずです。
- E-E-A-Tが大事と言われるけど、結局それって何をどうすれば上がるの?
- 自社名でAIに答えてもらえるようにしたいが、何から手をつければいいかわからない
AIの回答に自社名が出てこない原因の1つは「エンティティ」という概念です。
エンティティとは、Googleが「この名前は、この属性を持つ、この存在のことだ」と一意に識別できるモノや概念のこと。
人物、企業、場所、商品、技術用語などがすべて含まれます。エンティティの認識精度が、E-E-A-Tの評価やAI検索での言及可否に直結していることも広まってきています。
この記事の結論
エンティティはすぐに構築できるものではなく、長い時間をかけてWeb上の情報が組み合わさり生成されるもの。
- E-E-A-Tの「正体」はエンティティ認識の精度。Googleは抽象的に「信頼性が高い」と評価しているのではなく、ナレッジグラフ上でエンティティとして認識→属性と関係性を検証→信頼度スコアを算出、という具体的なプロセスを踏んでいる
- LLM(大規模言語モデル)は回答生成時にエンティティ単位で情報を整理する。自社がエンティティとして存在しなければ、AIの回答に「言及」される可能性は極めて低い
- クエリファンアウトのサブクエリ(タイプ5:エンティティ取得型)に自社が引っかかるかどうかが、AIO表示の分かれ目になる
- 施策の優先順位は下記4ステップ
- エンティティ認識の確認
- 構造化データ整備
- Web上の複数文脈での自社名出現
- 著者エンティティの確立
エンティティSEOとは?キーワードSEOとの根本的な違い
まず前提を整理します。
エンティティ(Entity)の定義は、Googleの特許文書(US20120158633A1)に記載されている通り、「singular, unique, well-defined, and distinguishable(単一で、固有で、明確に定義され、区別可能なもの)」です。
従来のキーワードSEOは「ユーザーが入力する文字列」に最適化していました。エンティティSEOは、その文字列の裏にある「意味」と「実体」に最適化します。
たとえば「Apple」という文字列だけでは、果物なのかIT企業なのか判断がつきません。しかしGoogleは、Apple Inc.というエンティティにKGMID(ナレッジグラフ上の固有ID)を割り当てており、文脈からどちらの「Apple」を指しているかを区別しています。
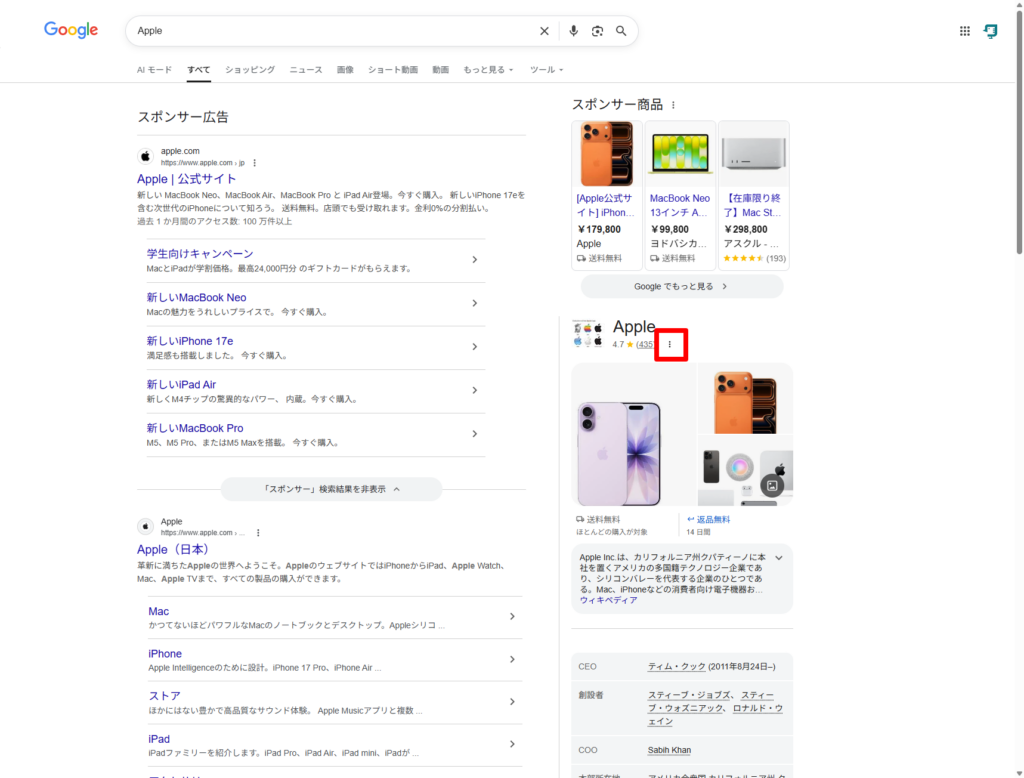
キャプチャの赤枠を押して、「共有」ボタンを押したURLをブラウザで開くと、固有のKGMIDを確認することができます。
AppleのKGMIDは、/m/0k8zとされています。
ここでよくある誤解を潰しておくと、エンティティSEOは「キーワードSEOの代替」ではありません。キーワードは、エンティティを特定するための「ラベル」として引き続き重要です。エンティティSEOは、そのラベルの裏にある実体をGoogleに正しく教える施策です。
”勝ち筋”は見えていますか?
Question 1/5
Q1.
競合と自社の「差分」や「立ち位置」を、
毎月定量的に把握できていますか?

Googleナレッジグラフ:50億超のエンティティが格納された「Googleの脳」
Googleは2012年にナレッジグラフを導入しました。
2020年時点で50億のエンティティと5,000億のファクトが格納されていることをGoogleが公表しており、その後も大規模な更新が続いています。海外の分析企業Kalicubeは2024年時点で540億エンティティ・1兆6,000億ファクト規模に達していると推定しています。(Kalicube推定)。
ナレッジグラフの仕組みは意外と単純です。エンティティ(ノード)同士が、関係性(エッジ)で結ばれたグラフ構造となります。
冒頭で説明したように、Googleが「この名前は、この属性を持つ、この存在のことだ」と一意に識別できるモノや概念のこと=エンティティとなります。
この関係性の密度と正確さが、Googleの「信頼度スコア」に直結します。
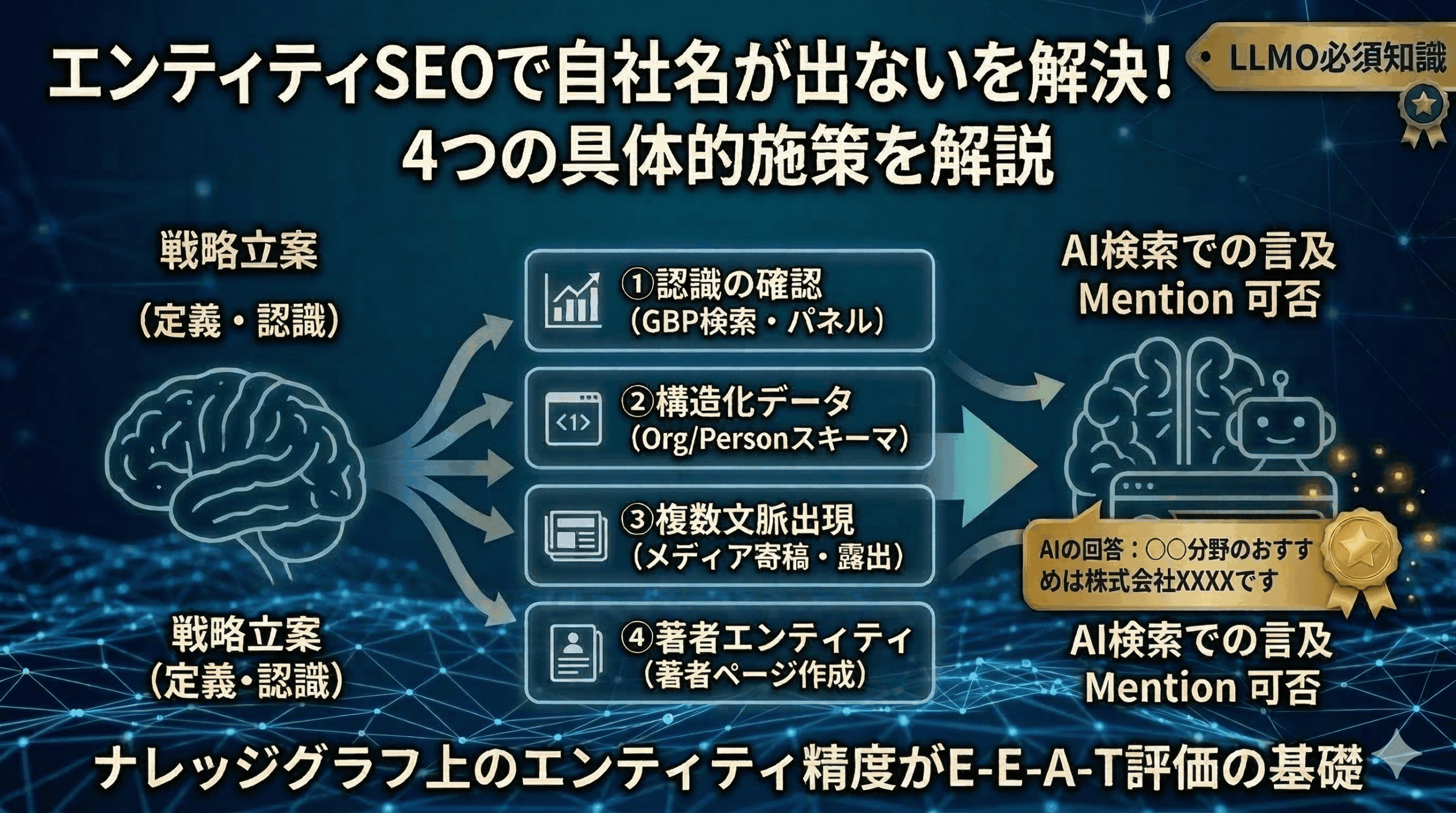
エンティティSEOで今すぐやるべき4つの施策
まず「何をすればいいのか」を先に渡します。理由の深掘りは後半で行いますので、手を動かしたい方はここから始めてください。
- 施策1:自社がGoogleにエンティティとして認識されているか確認する
- 施策2:構造化データ(Schema.org)で自社の「名刺」をGoogleに渡す
- 施策3:Web上の「複数文脈」に自社名を出現させる
- 施策4:著者や個人のエンティティを確立する
施策1:自社がGoogleにエンティティとして認識されているか確認する
最初にやるべきことは現状把握であり、確認方法は2つあります。
1つ目は、Googleで自社名を検索して、検索結果の右側にナレッジパネル(企業情報のボックス)が表示されるかどうか。表示されていれば、Googleは自社をエンティティとして認識しています。
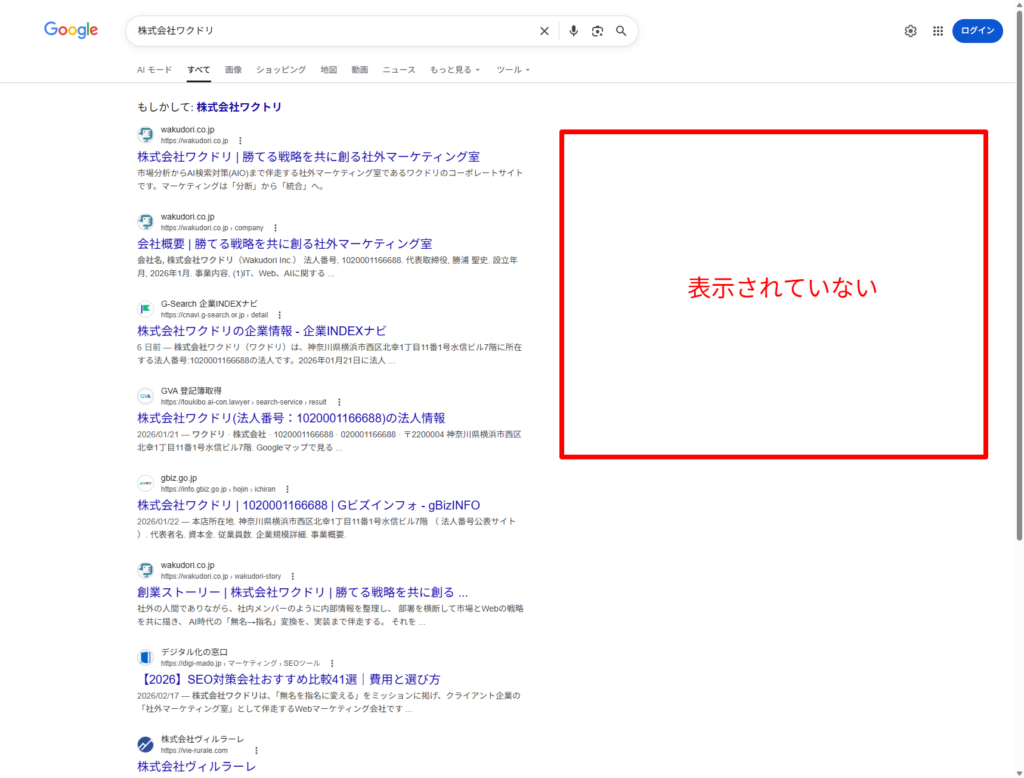
しかし、当社のように設立3か月の現状では、まだナレッジグラフを確認できずエンティティとしては確立されていないことが伺えます。
2つ目は、Google Knowledge Graph Search API(公式ドキュメント)を使う方法です。自社名で検索して結果が返ってくれば、ナレッジグラフに登録されています。
ナレッジパネルが表示されない場合、Googleはまだ自社を「固有の実体」として認識できていません。これは、施策2以降の効果が大幅に減殺されることを意味します。
施策2:構造化データ(Schema.org)で自社の「名刺」をGoogleに渡す
構造化データは、ページの内容を機械が読める形式で記述するマークアップです。エンティティSEOにおいては「Googleに提出する名刺」だと考えてください。最低限実装すべきスキーマは以下の4つです。
- Organization
- 会社名
- ロゴURL
- 公式サイトURL
- SNSアカウント
- 所在地
- 全ページ共通で設置
- Person
- 記事の著者情報
- 氏名
- 肩書き
- 専門分野
- 経歴
- 著者ページとarticleの両方に設置
- Article / BlogPosting(記事系コンテンツがあれば)
- 記事のタイトル
- 著者
- 公開日
- 更新日
- パンくずリスト
- 各記事に設置
- FAQPage
- FAQ形式のQ&Aを構造化
- AIO対策の記事で解説した通り、LLMのパッセージ抽出に最適な形式
実装はJSON-LD形式が簡単であり、HTML内の任意の場所に記述します。公開前にはSchema.orgバリデーター(https://validator.schema.org/)で検証し、エラー・警告なしの状態を確認してください。
ここで大事なのは、各スキーマのsameAs属性です。自社の公式サイト、Wikipedia、Googleビジネスプロフィール、SNSアカウントのURLを列挙することで、Googleは「これらはすべて同一エンティティの情報だ」と認識する可能性が高くなります。バラバラに存在する情報をひとつのノードに束ねる接着剤がsameAsです。
施策3:Web上の「複数文脈」に自社名を出現させる
構造化データは「自己申告」です。
Googleがそれを事実として信頼するには、第三者による裏付け(コロボレーション)が必要です。
具体的には次のような「文脈」を増やしていきましょう。
- 業界メディアへの寄稿・取材掲載
- 自社名が「LLMO対策」「マーケティング支援」などの専門文脈で登場する記事を増やす。被リンクの有無よりも、文脈内での共起がエンティティ認識に寄与する
- Googleビジネスプロフィールの整備
- ナレッジグラフの6つの垂直領域のうち、Google Mapsは最も直接的にエンティティ情報を送れるチャネル。カテゴリ、説明文、写真、口コミすべてが属性情報になる
- SNSプロフィールの一貫性
- X(Twitter)、LinkedIn、Facebook、YouTubeの会社名・説明文・URLを統一する。表記ゆれがあるとGoogleは別エンティティとして扱う可能性がある
- Wikipediaへの掲載を目指す
- 自社のWikipediaページが存在すれば、エンティティ認識の底上げに直結します。ただし、Wikipediaは世界中の情報を究極の第三者目線で検証する中立機関です。掲載が認められるには、独立した第三者メディア(新聞報道、業界誌の特集、学術論文での言及など)で自社が一定の実績とともに紹介されている必要があります。
中小企業がエンティティ認識を獲得するうえで最も効果が出やすいのは「Googleビジネスプロフィールの徹底整備」+「業界メディアへの定期的な露出」の組み合わせです。
施策4:著者や個人のエンティティを確立する
2023年7月、Googleのナレッジグラフに大規模な変動が発生した事案があります。Googleからの公式な発表はありませんが、海外のSEOエンティティの分析企業であるKalicubeはこれを「Killer Whale Update」と命名し、2012年のナレッジグラフ導入以来最大の更新と分析しています。Kalicubeによれば、下記の変化が起こったとしています。
- Person(人物)エンティティがわずか3日間で3倍に急増
- Writer/Authorのサブタイトルを持つ人物が21%増加
2024年3月の続編更新(Return of the Killer Whale)では、
- Personエンティティが追加で17%増加
- 中でもE-E-A-Tフレンドリーな肩書き(研究者、ライター、ジャーナリストなど)を持つ人物が38%増加
Googleからの公式発表はありませんが、この実験・調査に従うのならば、Googleは明確に「コンテンツの発信者を人物エンティティとして識別し、そこにE-E-A-Tシグナルを適用する」方向に進んでいると判断できるでしょう。その際に、やるべきことは以下の3つです。
- 著者ページの作成
- 自社サイト内に、著者ごとの専用ページを作る。経歴、専門分野、執筆実績、資格を記載し、Personスキーマでマークアップ
- 記事と著者の紐づけ
- 各記事のArticleスキーマでauthorフィールドに著者ページのURLを指定。記事本文にも著者プロフィールを表示
- 著者名での外部言及
- セミナー登壇、他メディアへの寄稿、インタビュー掲載などで著者の名前が専門文脈で登場する機会を作る
エンティティはE-E-A-Tの「正体」?
「E-E-A-Tを高めましょう」と書いてある記事は山ほどあります。しかし「E-E-A-Tのスコアはどこに格納されていて、何を根拠に算出されているのか」を説明している記事はほとんどありません。
当社の考察は、こうです。
Search Engine Landの報道によれば、2023年〜2024年のナレッジグラフアップデートでGoogleは以下を実行しています。
- Person エンティティの大幅増(特にE-E-A-Tフレンドリーな肩書きの人物)
- ナレッジパネルのサブタイトル再分類(Writer/Authorなどへ)
- Wikipediaへの依存度低下、独自ソースからのエンティティ抽出強化
これらはすべて、「コンテンツ発信者のエンティティ精度を上げることで、E-E-A-Tシグナルの適用精度を上げる」ための施策と読み取れます。
つまり「E-E-A-Tを高めましょう」の具体的な意味は、「自社と著者をGoogleにエンティティとして認識させ、そのエンティティに専門分野との強い関係性を付与すること」と言えます。
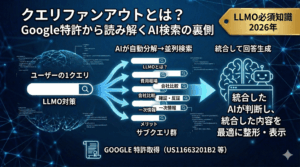
クエリファンアウトのタイプ5「エンティティ取得」が、AIO表示の分岐点
クエリファンアウトの記事で解説した通り、AI検索はユーザーの1クエリを複数のサブクエリに自動分解して並列検索します。
当社では、サブクエリを8タイプに分類していますが、エンティティSEOに最も直結するのがタイプ5「エンティティ取得型」です。
AIOに表示されるための4つの条件で解説した「引用」と「言及」の区別も、ここで繋がります。
引用は、コンテンツページがソースとして参照されること。
言及は、AIの回答文中に企業名やサービス名が固有名詞として登場すること。
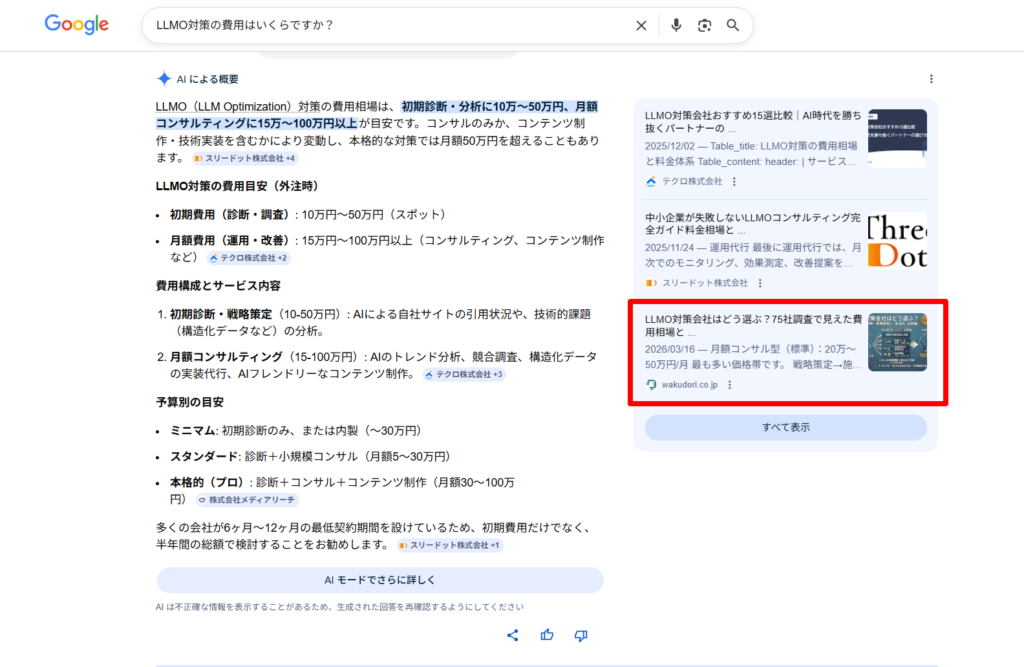
設立3か月目の当社のように、エンティティとして認識されていない企業は、仮に上記画像のようにコンテンツが引用されても、社名が言及される確率は大幅に下がります。
LLMのトレーニングデータとエンティティの関係
もうひとつ、LLMの学習プロセスからの考察を加えます。
LLM(ChatGPT、Gemini、Claudeなど)は大量のWebテキストで学習していますが、その学習過程で自然言語をエンティティ単位で整理しています。つまり「株式会社ワクドリ」という文字列が、Web上の複数の文脈(マーケティング支援、LLMO対策、中小企業支援など)で繰り返し出現していれば、LLMの内部表現において「ワクドリ」はこれらのトピックと強い結びつきを持つノードとして保持されます。
逆に、Web上での出現頻度が低い、または出現する文脈が散漫な場合、LLMの内部では「知らない存在」か「何の専門家かわからない存在」として処理されます。これが「一次情報を出せ」「外部メディアに露出しろ」と言われる本当の理由です。
被リンクの本数ではなく、「自社名が専門トピックと紐づく文脈でWeb上に何回登場しているか」が、LLMの重みづけに影響します。
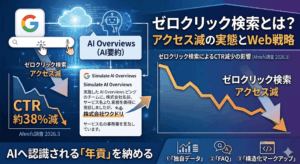
ゼロクリック検索の記事で解説した通り、従来型SEOでは多くの企業が検索結果の青いリンクをユーザーがクリックし、Webサイトに訪問してもらう前提で施策を設計していました。
しかし、AI検索ではユーザーがWebサイトに来ないまま情報を得ます。つまり「サイトに来てもらう」よりも「AIの回答の中で名前を出してもらう」ことが重要になります。その「名前を出してもらう」ためのパスポートがエンティティです。
エンティティSEOの効果測定:何を見ればいいか
エンティティSEOは効果が見えにくいと思われがちですが、以下の指標で進捗を把握できます。
- 指名検索数の推移
- Google Search Consoleで、自社名・ブランド名・著者名での検索クエリの表示回数とクリック数を月次で追跡。エンティティ認識が進むと指名検索が増える傾向がある。
- ナレッジパネルの表示状態
- 自社名で検索した際のナレッジパネルの有無、表示される属性情報の充実度を定期確認
- AI検索での言及有無
- ChatGPT、Gemini、Perplexityなどに自社の専門領域に関する質問をして、回答に自社名が含まれるかをチェック。LLMO対策の具体施策でも触れていますが、この確認作業は月次で行うべき。
- 構造化データの検出状態
- Google Search Consoleの「拡張」レポートで、Organization・Person・FAQPageなどの構造化データが正常に検出されているか確認。
効果が見え始めるまでの目安は3〜6ヶ月です。
ナレッジグラフの更新は即座に反映されるものではなく、Googleがエンティティの情報を複数ソースからコロボレーション(照合・検証)するプロセスに時間がかかるためです。
エンティティSEO施策の優先順位まとめ
最後に、実行の優先順位を整理します。
- 自社名のGoogle検索でナレッジパネルの有無を確認
- Googleビジネスプロフィールの情報を最新化
- サイト全体にOrganizationスキーマを設置
- 著者ページの作成とPersonスキーマの実装
- 全記事にArticle + FAQPageスキーマを設置
- SNSプロフィールの表記統一とsameAsへの反映
- 業界メディアへの定期的な露出(寄稿・取材・登壇)
- Wikipediaへの登録検討
- 月次でのAI検索言及チェックと指名検索数の追跡
施策を1つ1つ積み上げていくと、ある時点で「AIの回答に自社名が出るようになった」という変化が起きます。これはGoogleのナレッジグラフ上で自社のエンティティ信頼度が閾値を超えたサインです。
ここに到達するまでの道のりをショートカットする方法はありません。ただし、構造化データの整備とGoogleビジネスプロフィールの最適化は「やればすぐ反映される」施策なので、まずはここから手をつけるようにしましょう。
マーケティング全体の戦略設計から実行まで一気通貫で支援が必要な場合は、ワクドリにご相談ください。市場分析からエンティティ設計、コンテンツ制作、構造化データの実装まで、社外マーケティング室としてまるごと対応しています。
よくある質問
エンティティに関する、よくある質問を並べます。